模型架构
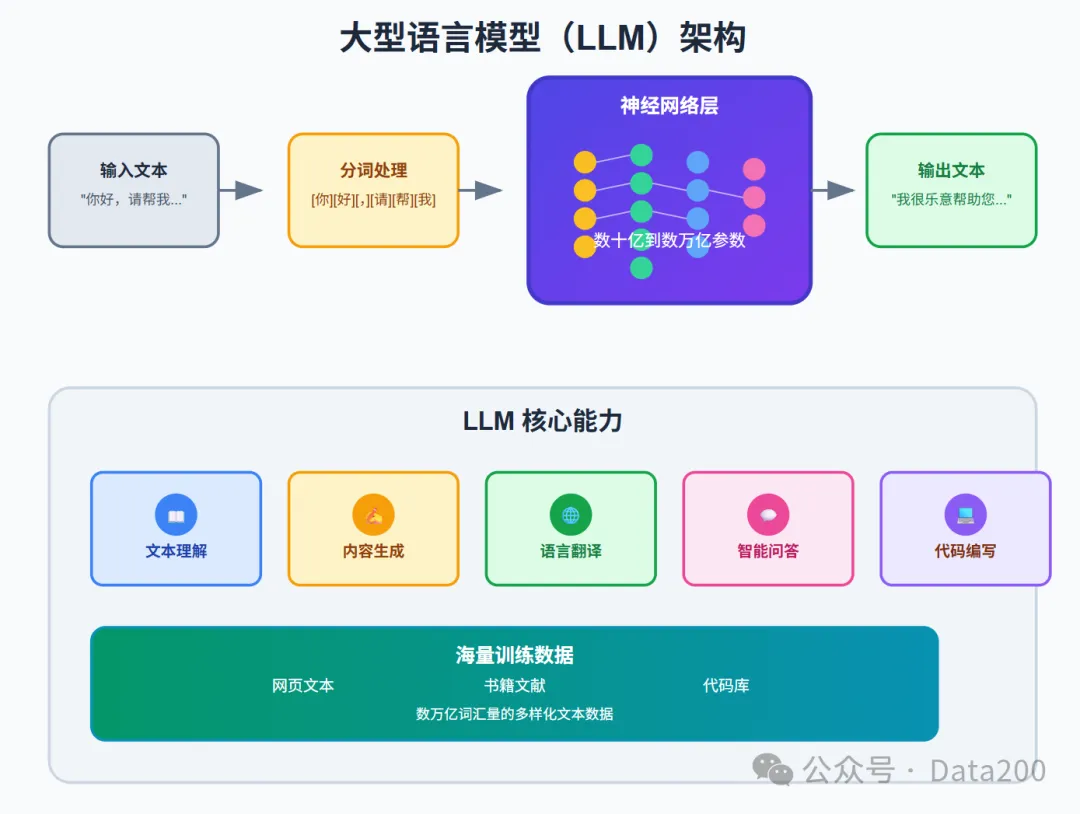
LLM 大语言模型
大型语言模型,英文全称 Large Language Model,简称 LLM。是指参数规模通常在数十亿到数万亿之间的深度神经网络,专门设计用于理解和生成人类语言。目前也是人工智能领域最热门的 AI,这些模型通过分析海量文本数据中的统计模式和语义关系,学会了语言的语法结构、语义内容和语用规则。LLM 的核心能力包括文本理解、内容生成、语言翻译、问答对话和代码编写等,代表了当前自然语言处理技术的最高水平。目前具有代表性的大模型包括 GPT-4,Claude-4,Gemini-2.5 等。
它通过在海量文本数据上进行自监督预训练,学习语言的语法和语义规律。目前最常用的架构是 Transformer 模型,它将输入文本分词并转化为向量,通过多头自注意力机制并行计算上下文相关性,从而捕捉长距离依赖关系。模型通常先进行无监督预训练,再通过微调或提示(Prompt)等方式适应具体任务。由于参数规模巨大(可能达到上百亿至千亿级),这些模型拥有“知识库”一样的海量参数,能生成流畅文本或完成复杂语言推理。
应用案例
大语言模型已广泛应用于各类文本生成和理解任务。如智能对话系统(例如 ChatGPT、Google Bard)利用 GPT 类模型进行开放式问答和助手功能;机器翻译、自动摘要、文本分类等传统 NLP 任务也采用预训练模型进行高质量处理。LLM 还被用于代码生成(如 GitHub Copilot)、信息检索与问答(增强搜索引擎),甚至生物医药(预测蛋白质结构)等领域。总之,只要涉及自然语言输入输出的场景,LLM 都成为底层技术,例如智能客服、辅助写作、知识图谱构建等。
未来发展趋势
随着规模效应递减,LLM 研究正向高效能方向发展:采用知识蒸馏、模型压缩(量化、剪枝)等技术以减小体积、降低推理延迟;多家公司已推出轻量版模型(如 GPT-4o、Claude 3.5 Sonnet、Gemini Flash),在性能几乎不减的同时显著加快响应。另一个趋势是多模态融合,最新模型已能同时处理文本、图像甚至音视频,这让 LLM 在图文问答、智能助手等场景中更具实用性。同时,增强推理能力也是重点,例如 OpenAI 的 o1 模型通过链式推理技术提升了数学和科学题解答能力。未来 LLM 将继续在提升效率(如半精度计算、定制化微调)、增强可靠性(降低偏见、提高可解释性)以及垂直领域应用(医疗、金融等专业模型)方面展开研究,以满足多样化需求。
Transformer 架构
Transformer 最早由谷歌于 2017 年在《Attention Is All You Need》论文提出,并且迅速成为自然语言处理(NLP)领域的标配,也是现今所有大模型的核心架构。其革命性的自注意力机制彻底改变了序列建模的方法。与传统的循环神经网络(RNN)不同,Transformer 能够并行处理序列中的所有位置,通过注意力权重矩阵捕获任意距离的依赖关系。这种架构设计不仅提高了训练效率,还显著增强了模型对长序列和复杂依赖关系的建模能力。
Transformer 是一种基于多头自注意力(Multi-Head Attention)机制的深度学习架构,其核心思想是为序列中每个位置计算与所有其他位置的相关性,从而并行建模长距离依赖。具体地,Transformer 将输入序列转为向量(Embedding),并在每一层通过查询(Query)-键(Key)-值(Value)机制执行注意力计算,同时使用多组头(multi-head)扩展表达能力。每个注意力子层之后再接一个前馈全连接网络,然后进行层归一化和残差连接。这种设计使 Transformer 无需循环结构,即可对序列并行处理,大幅加速训练。Transformer 模型通常由一个或多个编码器-解码器堆栈组成,编码器负责提取输入特征,解码器结合上下文生成输出。
应用案例
Transformer 已经成为众多智能应用的基石。NLP 领域中,几乎所有主流模型(如 BERT、GPT 系列、T5、Pegasus 等)都基于 Transformer,用于机器翻译、文本分类、问答系统、摘要生成等任务。在计算机视觉中,ViT 模型为图像分类、目标检测和生成对抗网络等场景带来了优异表现。Transformer 还被用于语音识别与合成(如 Speech-Transformer、Whisper)、时间序列预测、基于注意力的推荐系统、强化学习决策模型,以及 AlphaFold 等蛋白质结构预测中。可见,Transformer 架构广泛应用于语言、视觉、音频等多模态任务,帮助多个产品和平台(如云翻译服务、智能语音助手、搜索引擎等)提升了理解和生成能力。
未来发展趋势
Transformer 未来的发展趋势主要集中在效率和扩展能力上。一方面,为降低计算开销,研究者在探索更高效的注意力机制(如稀疏注意力、线性化注意力)和更紧凑的模型(剪枝、量化、蒸馏等),同时提供多种尺寸的模型以适应不同硬件。另一方面,多模态 Transformer(融合文本、图像、音频等)成为热点,使模型能在更丰富的场景中工作。学术界也在研究更灵活的结构,例如混合专家的 Transformer(参见下文 MoE)、图 Transformer,以及与记忆网络结合的模型。未来,Transformer 架构有望进一步提升大规模分布式训练、长上下文处理能力,并与强化学习或神经网络可编程技术相结合,以应对更多复杂任务。
![]()
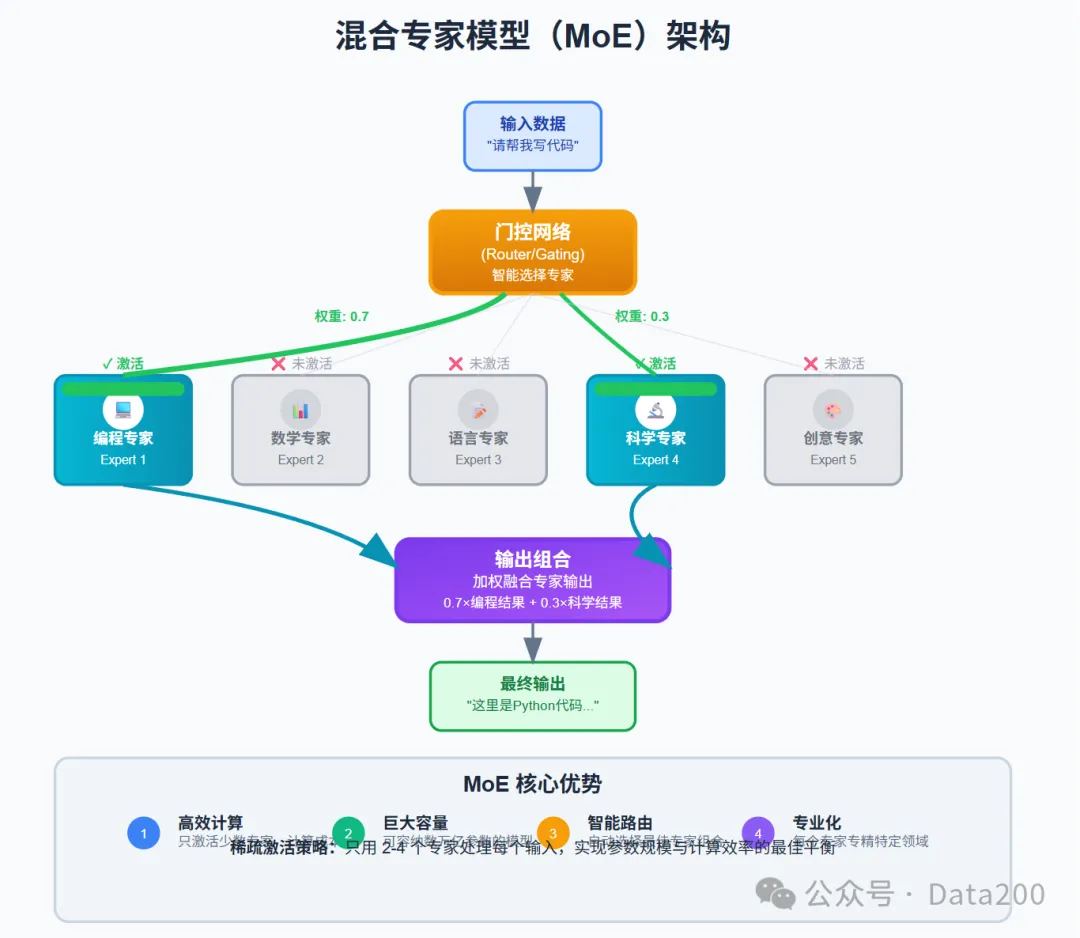
混合专家模型(MoE)
混合专家模型,是一种能够在保持计算效率的同时,大幅增加模型准确率的架构设计。混合专家模型包含多个专门化的子网络(专家)和门控网络,在处理任何用户输入时只激活其中一部分专家,也就是通过门控网络将任务分解后,激活部分特定专家完成任务。通过这种稀疏激活策略,既确保了任务的精准性,又提升了任务完成效率,MoE 模型能够拥有数万亿参数的理论容量,但实际计算成本仅相当于激活专家的总和,实现了参数规模与计算效率的平衡。
混合专家模型(Mixture of Experts, MoE)是一种条件计算架构:它在神经网络中引入多个“专家”子网络和一个路由器(gate),输入数据在路由器控制下被分配给部分专家进行处理,而其它专家保持不活跃。具体地,在 Transformer 的每个前馈层中使用 MoE 层替代传统的全连接层,一个 MoE 层包含若干个并行的前馈神经网络(专家)以及一个门控网络。路由器根据输入的特征计算每个专家的相关性,只激活 Top-$k$ 个专家来处理该输入。这种设计使得模型具有极大的参数容量,但每次前向传播只需要计算少量专家,极大降低了推理计算量。简而言之,MoE 通过稀疏激活的方式,在给定计算预算下实现更大的模型规模和学习能力。
应用场景
目前 MoE 主要用于需要极大模型容量但又受限于计算资源的场景。Google 在多语言机器翻译(GShard 项目)和通用语言理解(GLaM)中采用了 MoE 架构,以提升模型规模和性能;OpenAI 在后续实验性模型(如 Chain-of-Thought 的大型模型 o1 系列)也探索了 MoE 技术。行业开源方面,Mistral 的 Mixtral 用于文本生成,使用了 8 个 7B 专家的 MoE 结构。此外,MoE 理念也被用于计算机视觉(通过专家分支处理不同特征)和个性化推荐等领域,用于提高模型容量而不成比例增加计算负担。随着工具链的发展和生态成熟,越来越多的模型平台开始支持 MoE 层,可灵活地应用在 Transformer 等大模型中。
未来发展趋势
MoE 研究的重点包括更高效的路由策略和更稳定的训练方法。当前技术难点之一是负载均衡:由于不同输入可能被分配到不同专家,单个专家的有效批大小减少,需要设计路由正则化(如 Z-loss)来保持平衡。未来工作可能探索层次化 MoE(专家嵌套专家)和动态专家容量,以及减少分布式通信开销的新技术。另一个趋势是将 MoE 扩展到更多场景,如视觉-语言多模态模型、长期记忆网络等。此外,研究者也在尝试结合 MoE 与检索机制或可微分编程,以进一步提升模型的灵活性和可扩展性。随着硬件和编译器支持的增强,可预见 MoE 将成为构建超大模型的重要工具,为下一代 AI 系统提供容量与效率兼顾的解决方案
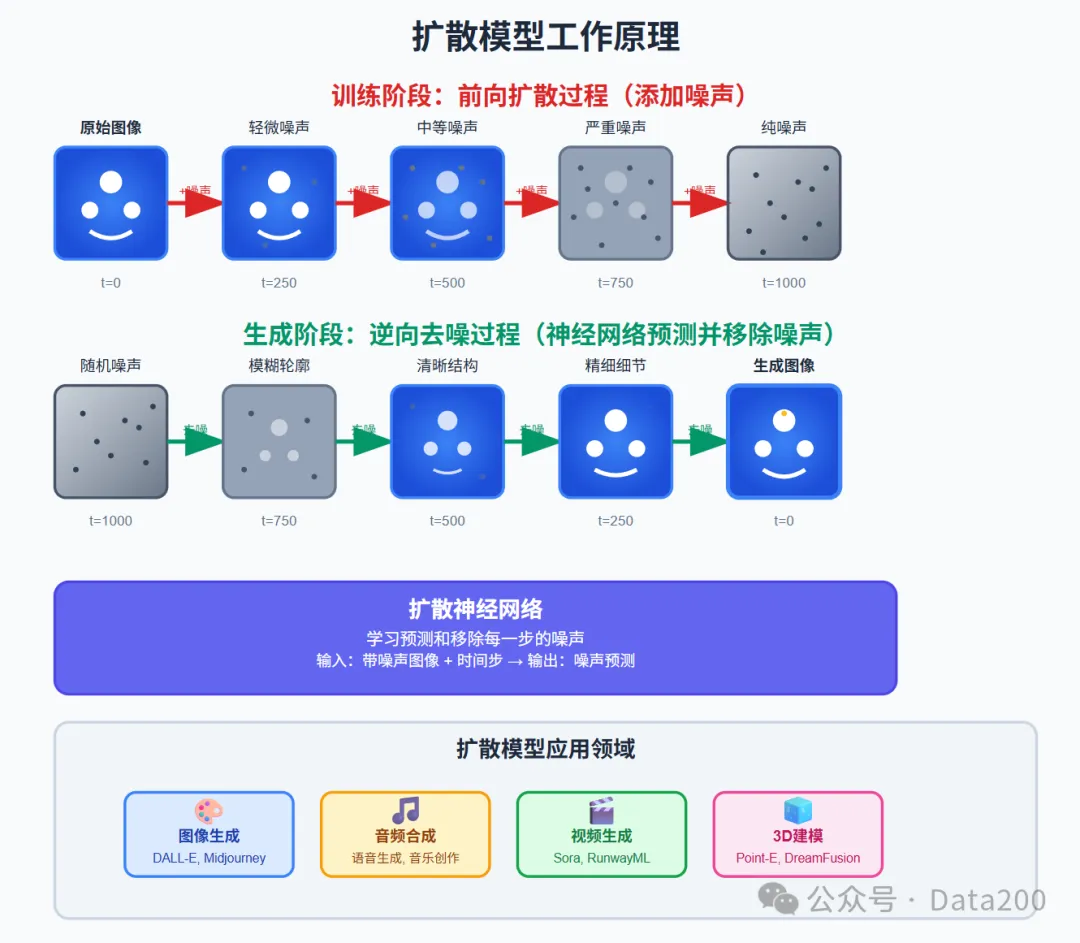
扩散模型(Diffusion Model)
扩散模型是一类生成式 AI 模型,在图像和音视频领域广泛应用,通过模拟数据的噪声扩散过程来学习数据分布,简单说就是模型根据用户输入,将数据从无到有,从无序到有序的完成特定图像或音视频生成任务。训练阶段,模型学习如何将噪声逐步添加到原始数据中;生成阶段,模型从随机噪声开始,通过逆向扩散过程逐步去除噪声,最终生成高质量的数据样本。这种方法在图像生成、音频合成等领域取得了卓越的效果,生成内容的质量和多样性都达到了前所未有的水平。
扩散模型是一类生成式模型,其核心思想是将数据分布逐步添加噪声,然后学习反向去噪过程来恢复数据。具体而言,前向扩散过程将原始样本逐步加噪(通常是高斯噪声),最终将其转变为近似均匀的噪声分布。反向扩散过程则训练一个神经网络(如 U-Net)来逐步去除噪声,每一步预测当前图像中的噪声或直接重构干净图像。在训练时,模型通过最小化与真实噪声的差异(MSE 损失)或变分下界(VLB)来学习去噪函数。该方法不依赖对数据分布的显式假设,而是通过迭代更新实现高质量采样。扩散模型可以看作一种逐步生成过程,其理论基础与随机微分方程和能量基模型密切相关。
应用案例
扩散模型在各类生成任务中表现出色:图像生成方面,DALL·E 2、Stable Diffusion、MidJourney 等产品能够根据文本提示创作艺术风格的图像;医疗影像、卫星图像超分等专业领域也开始引入扩散技术提高图像质量。音频生成方面,扩散模型用于语音合成和音乐创作(如 DiffWave、WaveGrad、AudioLDM 等)。在视频领域,扩散模型可用于短视频或动画生成(例如 Imagen Video)。此外,扩散思想还被用于分子结构生成、三维形状建模(如 Google 的 DreamFusion)等任务。扩散模型的高灵活性和稳定性使其成为艺术创作、娱乐内容生成以及科研辅助设计等场景的重要工具。
未来发展趋势
未来扩散模型的发展趋势包括加速采样和跨模态扩展。研究者致力于减少采样步骤数,例如通过蒸馏方法训练更少迭代的生成网络(“进度式蒸馏”)或设计确定性采样方法(如一致性模型)来提升速度。多模态方面,扩散模型将与大语言模型或其他感知模型结合,实现语音-图像-视频等跨模态生成。扩散技术也在向更高分辨率、三维数据和物理模拟方向扩展,应用于科学计算和医疗等领域。总之,扩散模型作为一种通用的生成框架,未来会继续优化效率并与其他 AI 技术融合,为更多创作和决策任务提供可靠、高质量的生成能力。